







TwinBench: Toward unbiased Virtual Cells benchmarks
Abstract
TL;DR
Benchmarks are a cornerstone of Machine Learning community developments. They structure model developments, ensuring that their development aligns with societal challenges and provide confidence in the domain's maturity for real-world applications.
AI driven virtual cell models are a fast emerging field and current benchmarks don’t yet have the maturity nor the robustness seen in other ML domains, such as images or text, a concern increasingly recognised in the research community. As the field matures, it’s crucial to rethink how we evaluate and compare models - not just to chase better numbers, but to ensure real scientific insight that translates into future patient impact.
DeepLife has developed TwinBench, a benchmarking framework for virtual cells, assessing the quality of generation using recommendation systems and correcting for common and important biases in current benchmarks.
In this blog, we explain the current limitations on actual benchmarks before introducing TwinBench and share how DeepLife is contributing to open, reproducible tools so the whole community can benchmark models more meaningfully.
Current benchmark biases
Machine learning models are prone to a number of well-known failure modes - systematic ways in which they can produce misleading or unreliable results. The most familiar is overfitting: when a model memorises the training data, but fails to generalise to new inputs. Another important failure mode is mode collapse, often seen in generative models (more specifically GANs: Engel et al., 2021). Here, the model produces very similar outputs regardless of the input - effectively ignoring the information it is given.
This phenomenon of “input independent models” is not only present in generative models, but appears across machine learning under different names
- In recommendation systems: “popularity bias" (Feng et al., 2023) - recommending the same items to everyone
- In classification: “major classifier bias” (Rawat et al, 2022) - favouring the most common outcome
Across all cases, the root problem is the same: the model is not meaningfully using its input. These failure modes are easy to detect in domains like image generation, but much more complex in high dimensionality biological data such as RNA-seq.
Current virtual cells benchmarks don’t account for this effect and might mistake memorisation for true predictive performance, leading to an inflated sense of progress.
TwinBench addresses this by detecting when models ignore their inputs and adjusting evaluation metrics to account for this bias.
How does TwinBench work?
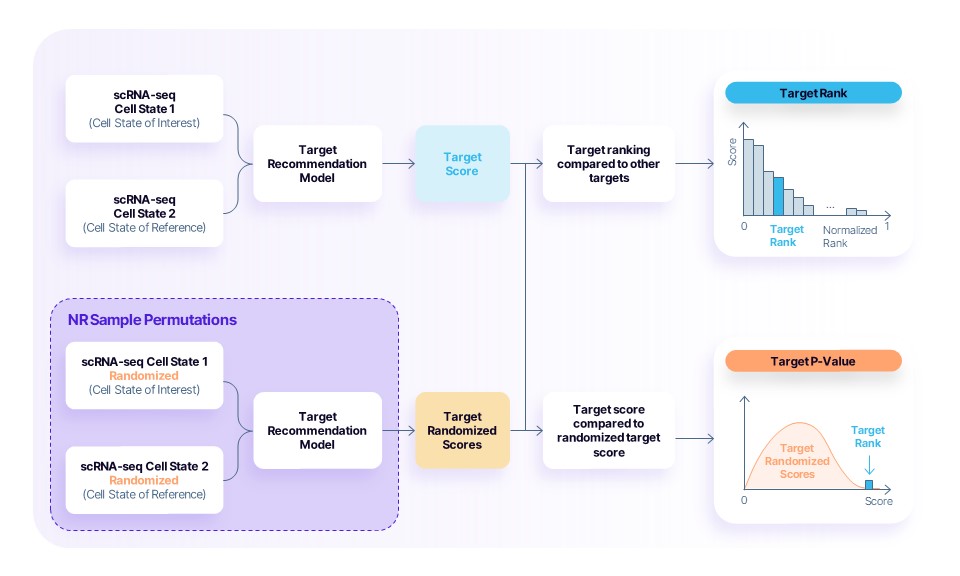
TwinBench introduces two key ideas:
1. Evaluating predictions using ranking-based metrics
2. Correct for input-agnostic behaviour (popularity bias / mode collapse)
1. Evaluate virtual cells with recommendation system metrics
Traditional evaluation frameworks rely on similarity scores (e.g. R2 Pearson correlation) between predicted and true samples. TwinBench instead asks a more practical question: is my prediction closest to the correct biological outcome, compared to all other possible outcomes?
To do this:
- Each prediction is compared against all real samples, computing the distance of the predicted expression to all true samples across the perturbations
- These samples are ranked by similarity, sorted with the closest distance on top, and we recover the rank of the true perturbation
- The position of the correct sample in this ranking is recorded
This approach provides a more robust and interpretable measure of performance, especially in high dimensional data.
2. Correct for input-agnostic behaviour
Popularity bias, or mode collapse, occurs when the model produces outputs that are largely independent of its inputs. In drug discovery, detecting this effect is critical to distinguish between predictions that reflect genuine biological reasoning and those that are merely artefacts of the model. This distinction is essential if we want to trust the model’s predictions in clinical settings.
How we detect popularity bias
The core idea is quite simple:
“If a model doesn’t use the information in the input for its predictions, then removing it won’t affect the model predictions.”
First, we randomise the input data. Imagine an image, if the pixels are randomized, the distribution of red, blue, green is the same but what makes the image is removed.
We then compare the score of the model with the original, real sample (with R2 for example) and the randomized input version. If the randomized sample scores higher or equal to the original, then the model is not exploiting the information in the input.
We then replicate this experiment 100-1000 times to estimate if this observation is statistically robust (giving an empirical p-value).
If performance remains unchanged, the model is likely not using the input in a meaningful way.
Building an unbiased score
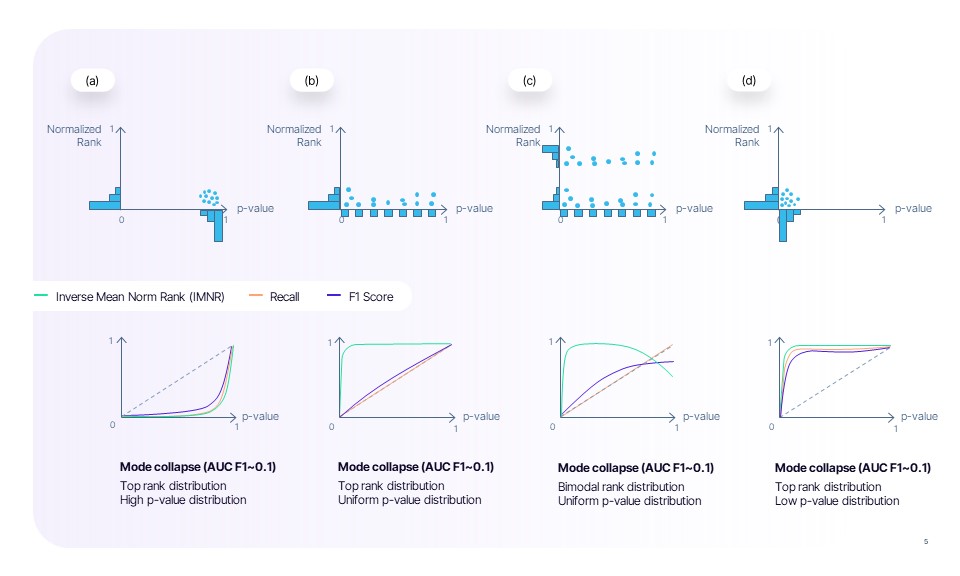
Standard ranking metrics (Recall at K, Precision at K and F1-score at K) are typically evaluated at a fixed cutoff (e.g. top K results). The “at K” correspond to the top K elements of the list in which we compute the precision, recall or F1-score (blog post).
TwinBench adapts this by:
- Replacing the fixed cutoff (“at K” threshold) with a confidence threshold (“at p-value”)
- Measuring performance only where the model demonstrably uses its input
The final metric is the area under the curve of the F1-score across all p-values (AUC-F1 score). This ensures the score reflects both accuracy and reliability of the model’s reasoning.
Future outlook & open sourcing
As the virtual cell field continues to evolve, improving how we evaluate models will be just as important as the models themselves. Rigorous benchmarks are key to driving results that capture real biology and accelerate translation into experimental and patient-relevant insights.
TwinBench embodies this shift, focusing on a model’s ability to learn from inputs and generate meaningful biological predictions beyond headline performance metrics. At DeepLife, we believe that benchmarks are the foundations to organize a community around a shared vision and bridge the gap between model developers and model users.
By opening sourcing TwinBench, we aim to align the community around shared standards, support the rising virtual cell community and push the boundaries of what virtual cells can achieve.
Get involved
Explore the TwinBench framework and test it on your own models. Together we can build better evaluation practices that ensure virtual cell models deliver real scientific insight.