







TwinCell: AI-based Virtual Cell for reliable and interpretable Target Identification
Abstract
Curing a disease starts with deeply understanding it. Choosing the right biological target is the single most important decision in drug discovery, as this first step determines which hypotheses are developed and which experiments are run. Every year, billions are invested in programs that never reach patients - not because the science wasn’t promising, but because the initial decisions about which targets to pursue in this process were flawed.
60% of clinical trial failure is due to the wrong target choice
“Analyses of clinical trial data from 2010 to 2017 show four possible reasons attributed to the 90% clinical failures of drug development: lack of clinical efficacy (40%–50%), unmanageable toxicity (30%), poor drug-like properties (10%–15%), and lack of commercial needs and poor strategic planning (10%)” - Sun et al. (2022)
Although clinical efficacy is mostly related to the target, unmanageable toxicity is only partially, so we could estimate that up to 60% of clinical trial failures can be traced back to selecting the wrong targets. While toxicity and drug properties play a role, the largest driver of failure remains a lack of clinical efficacy - meaning the biology itself was misunderstood from the start.
Target identification begins with a deep understanding of cell mechanisms - how genes, proteins and pathways interact to drive disease. The idea of “simulating” cells computationally first emerged in 2001 (Loew & al (2001)), treating biology as a system that could be modeled and predicted as we do with mechanical ones. But this has proven extremely difficult:
- Biological systems are incredibly complex
- Experimental data is limited and expensive
- Many underlying mechanisms are still unknown
Recently, an alternative approach has emerged: AI-based Virtual Cells (AIVC) (Bunne, C. et al. (2024), Rather than relying entirely on predefined biological rules, these models learn directly from experimental data, much like how children learn by observing the world around them (. the same core concept as “world models”).
In this blog, we will present the state-of-the-art of AI-based Virtual Cell models and their current shortcomings, before introducing how we solved these limitations with TwinCell and we will conclude with results from our recent preprint.
AI-based Virtual Cells and their current limitations
AI-based Virtual Cells (AIVC) aim to model how a cell behaves under different conditions. In essence, they are causal models: rather than relying on correlations, they aim to predict the effects of perturbing a biological system.
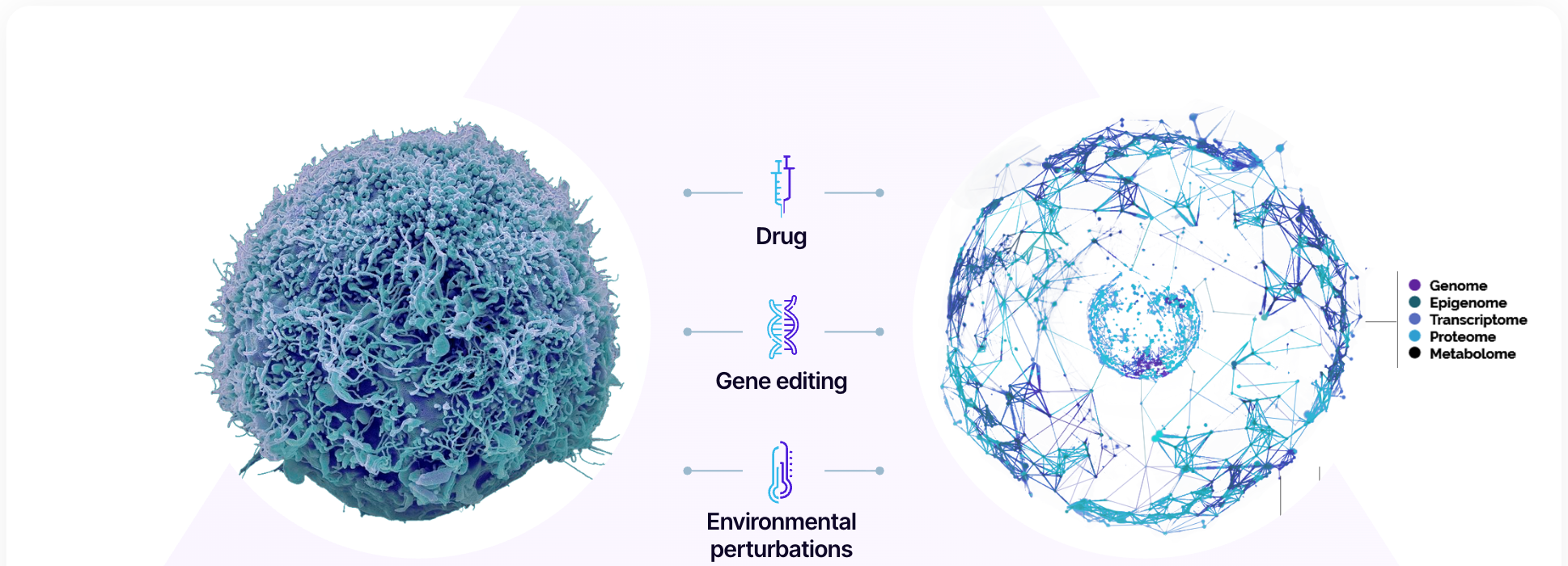
This causal understanding is learned from perturbation data on cell lines - such as knocking out a gene using CRISPR or introducing a drug into the cell medium - and observing the resulting changes downstream.
The challenge of biological world model
Early approaches to virtual cells, such as scGen (Lotfollahi et al 2019), were inspired by “world models” used in robotics and video games, where models learn a compact representation of the environment, then simulate how it evolves over time. In those domains, the approach has been spectacularly successful: a game engine or robot can generate millions of perfectly labelled frames, every variable is observable and the laws of physics are known.
Cellular biology operates under a fundamentally different regime: data is scarce and expensive to generate, observations are destructive, and the underlying laws are only partially known (see table below).
In short, biology is a far more constrained and uncertain environment for building predictive models.
Current limitations of AI-based Virtual Cells
The strong technical limitations on the data and knowledge of cell mechanisms translate into three main challenges for existing approaches:
- Outperformed by linear models: Surprisingly, large complex models often fail to outperform simple linear models on cell line data. This is because complex models tend to overfit in high dimensions when data is scarce, so simple methods can appear more effective, even if they lack mechanistic modelling.
- Poor generalization: Many models struggle to transfer what they learn (or fail to generalise) to new targets, unseen cell types and real disease biology. This limits their usefulness in real-world drug discovery.
- Black-box predictions: Most models work as “oracles,” delivering results without clear explanations or connection to known biology. This makes it difficult for researchers to assess biological plausibility or design follow-up experiments.
To address these limitations, alternative architectures are mandatory to achieve the performance required for reliable target identification.
How TwinCell addresses these challenges
TwinCell is a causal Virtual Cell model that addresses these limitations by combining three complementary sources of biological knowledge:
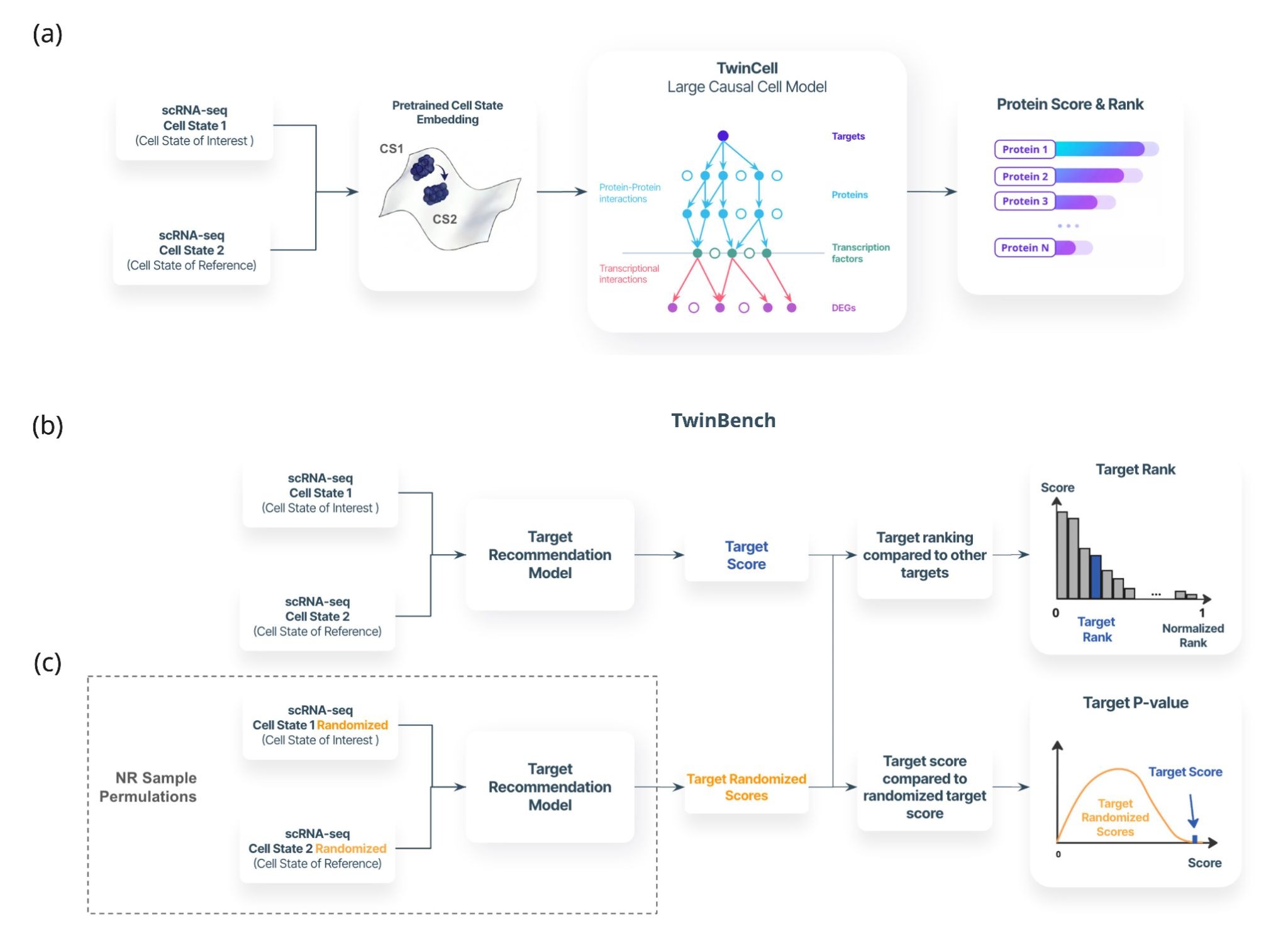
1. Cellular context through foundation models. TwinCell uses embeddings from Geneformer, a foundation model pretrained on millions of single cells, to encode cell-type identity and activation state. This provides a rich biological context in which the predictions are made.
2. A biologically grounded multi-omics interaction network: All signal propagation is constrained to pass through a network of 15,000 proteins and 201,000 experimentally validated interactions. This prevents the model from inventing biologically implausible routes, enables reasoning about targets never seen during training through their known network neighbours, and provides a shared scaffold for generalisation across different cell types.
3. Causal learning from perturbation data with cell-type-specificity: TwinCell is trained end-to-end on large scale perturbation datasets (Tahoe-100M). Importantly, it learns context-dependent interactions modulated by the foundation model embeddings. The interactome defines where signals can flow; the embeddings determine if and how strongly they flow in a given cellular state.
This combination forms the core of TwinCell's cell-state-specific causal model: where the same biological network behaves differently depending on the cellular environment.
From simulation to direct target identification
Most virtual cell approaches require a costly optimization loop to perform target identification: simulate many candidate perturbations, compare each outcome to the desired cell state, and rank by proximity.
TwinCell bypasses this by solving the inverse problem directly: rather than forward-simulating every possible intervention, it identifies the upstream regulators most likely to drive a desired change in cell state in a single step. Because predictions are decomposed over signalling paths through the interactome, each result is mechanistically interpretable, not just a score.
Key Performance Results
TwinCell was evaluated using TwinBench, a three-tier validation framework that tests virtual cell models under progressively harder, drug-discovery-realistic scenarios, from held-out cell lines to true out-of-distribution clinical predictions.
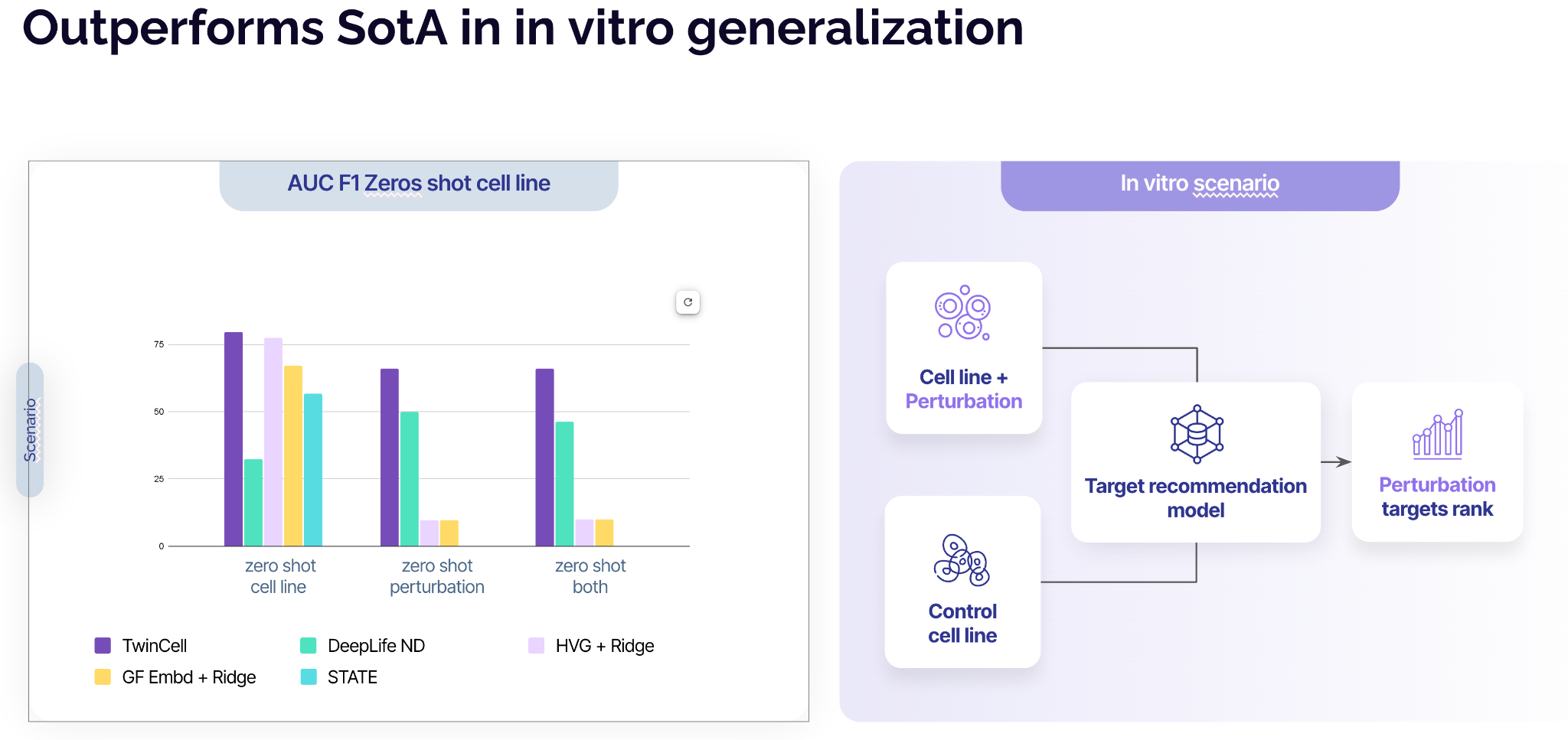
- Outperforming leading methods in zero-shot settings. Across five therapeutic areas (SLE, Parkinson's, psoriasis, Crohn's disease, ulcerative colitis), TwinCell consistently outperforms state-of-the-art virtual cell models, linear baselines, and network-based approaches in recovering FDA-approved drug targets, achieving an AUC of 0.79 in zero-shot cell-line prediction.
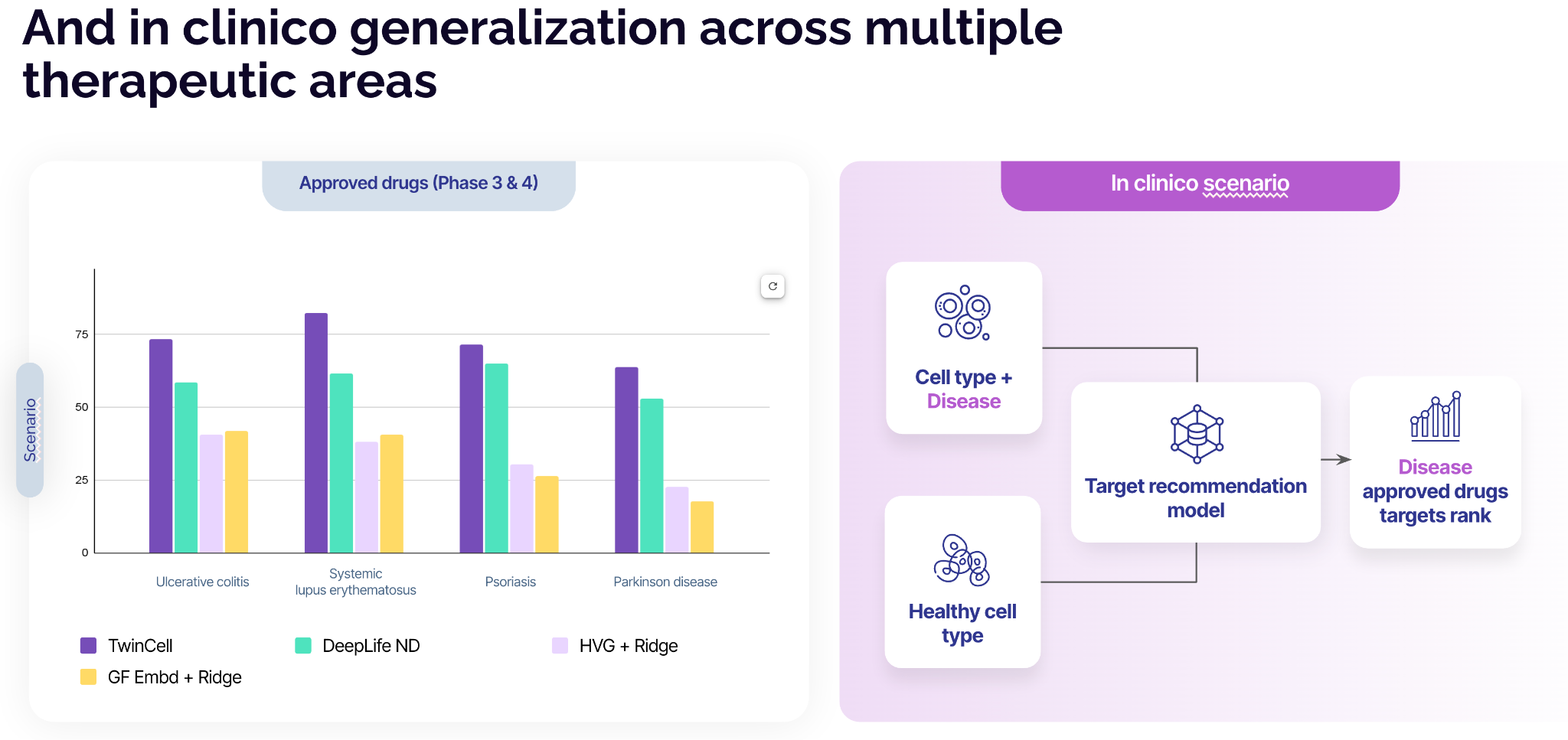
- Generalising from cancer cell lines to patient-derived disease tissue. In retrospective clinico analysis, TwinCell identifies validated drug targets not present in its training set. In SLE, it achieves an AUC of 0.76, recovering approved targets across blood, brain, skin, and intestinal cell types, without any disease-specific retraining.
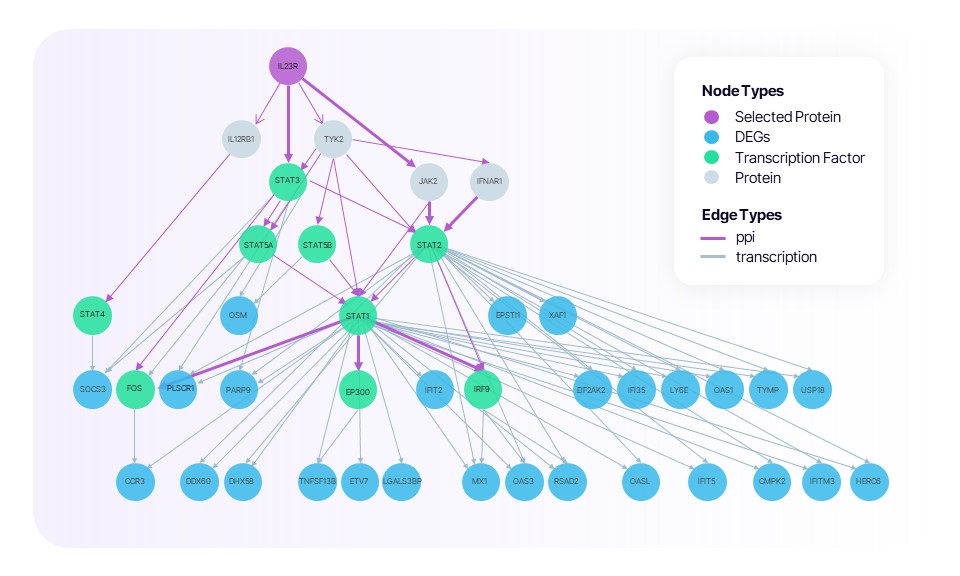
- Interpretable causal pathways for every prediction. For any predicted target, TwinCell extracts the most probable signalling routes through the interactome, enabling researchers to evaluate biological plausibility and design validation experiments. In SLE, the model reconstructs the chain IL23R → TYK2 → STAT1 → TNFRSF13B (BAFF), a pathway independently supported by clinical trial data the model was never exposed to.
Strategic impact
Target selection is the most critical - and failure prone - step in drug discovery. TwinCell changes the economics by improving this decision making process.
- Fewer failed programs: Better upstream target choices reduce late-stage attrition, lowering R&D costs and accelerating pipelines.
- Earlier risk reduction: By quantifying target probability before committing to costly validation, TwinCell enables faster, more confident go/no-go decisions.
- First-in-class opportunities: Generalisation to unseen targets and novel cell contexts opens mechanisms that competitors haven't explored.
More broadly, TwinCell is a step toward digital biology: a foundation for true digital twins of human biology. It moves us from correlation to causation, from black-box predictions to interpretable, actionable insight.
Looking ahead, DeepLife envisions a lab-in-the-loop paradigm where TwinCell generates novel target hypotheses that are iteratively refined through experimental feedback. Over time, this enables the construction of high-confidence causal cell models across various indications, positioning virtual cells as translational tools bridging high-throughput in vitro experiments and clinical decision making.
Interested in trying it for yourself?
Join the waiting list to get exclusive access to the alpha of the TwinCell API